如果定义一个概念需要用到这个概念本身,我们称它的定义是递归的(Recursive)。例如:
- frabjuous
an adjective used to describe something that is frabjuous.
这只是一个玩笑,如果你在字典上看到这么一个词条肯定要怒了。然而数学上确实有很多概念是用它自己来定义的,比如n的阶乘(Factorial)是这样定义的:n的阶乘等于n乘以n-1的阶乘。如果这样就算定义完了,恐怕跟上面那个词条有异曲同工之妙了:n-1的阶乘又是什么?是n-1乘以n-2的阶乘。那n-2的阶乘呢?这样下去永远也没完。因此需要定义一个最关键的基础条件(Base Case):0的阶乘等于1。
0! = 1
n! = n · (n-1)!
因此,3!=3*2!,2!=2*1!,1!=1*0!=1*1=1,正因为有了Base Case,才不会永远没完地数下去,有了1!的结果我们再反过来算回去,2!=2*1!=2*1=2,3!=3*2!=3*2=6。下面我们用程序来完成这一计算过程。我们要写一个计算阶乘的函数factorial,和以前一样,首先确定参数应该是int型的,返回值也就是计算结果也应该是int型的。先把Base Case这种最简单的情况写进去:
int factorial(int n)
{
if (n == 0)
return 1;
}如果参数n不是0应该return什么呢?根据定义,应该return n*factorial(n-1);,为了下面的分析方便我们引入几个临时变量把这个语句拆分一下:
int factorial(int n)
{
if (n == 0)
return 1;
else {
int recurse = factorial(n-1);
int result = n * recurse;
return result;
}
}factorial这个函数居然可以自己调用自己?是的。自己直接或间接调用自己的函数称为递归函数。这里的factorial是直接调用自己,有些时候函数A调用函数B,函数B又调用函数A,也就是函数A间接调用自己,这也是递归函数[10]。如果你觉得迷惑,可以把factorial(n-1)这一步看成是在调用另一个函数--另一个有着相同函数名和相同代码的函数,调用它就是跳到它的代码里执行,然后再返回factorial(n-1)这个调用的下一步继续执行。我们以factorial(3)为例分析整个调用过程,如下图所示:
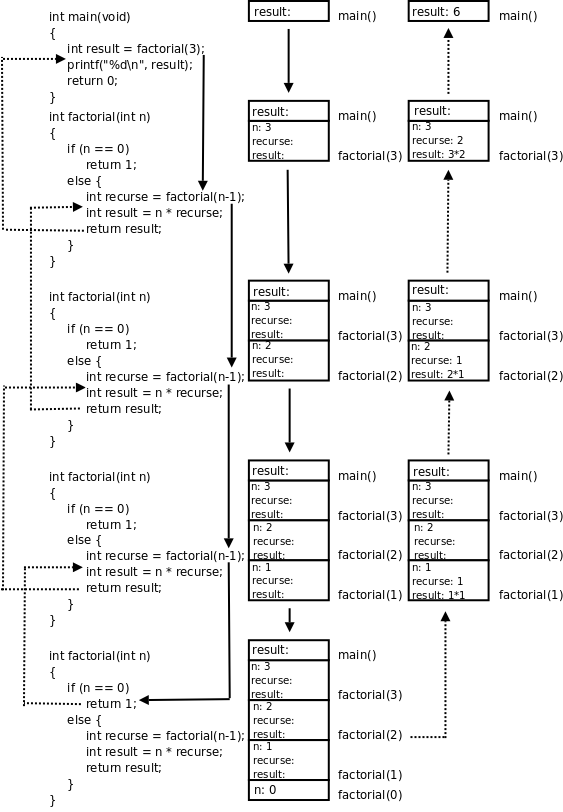
图中用实线箭头表示调用,用虚线箭头表示返回,右边的框表示在调用和返回过程中各函数调用的局部变量的变化情况。
main()有一个局部变量result,用一个框表示。调用
factorial(3)时要分配参数和局部变量的存储空间,于是在main()的下面又多了一个框表示factorial(3)的参数和局部变量,其中n已初始化为3。factorial(3)又调用factorial(2),又要分配factorial(2)的参数和局部变量,于是在main()和factorial(3)下面又多了一个框。“局部变量与全局变量”一节讲过,每次调用函数时分配参数和局部变量的存储空间,退出函数时释放它们的存储空间。factorial(3)和factorial(2)是两次不同的调用,factorial(3)的参数n和factorial(2)的参数n各自有各自的空间,虽然它们的变量名相同都是n,虽然我们写代码时只写了一次参数n,但运行时却是两个不同的参数n。并且由于调用factorial(2)时factorial(3)还没退出,所以两个函数的参数n同时存在,所以在原来的基础上多画一个框。依此类推,请读者对照着图自己分析整个调用过程。读者会发现这个过程和前面我们用数学公式计算3!的过程是一样的,都是先一步步展开然后再一步步收回去。
我们看图右边表示存储空间的框的变化过程,随着函数调用的层层深入,存储空间的一端逐渐增长,然后随着函数的层层退出,存储空间的这一端又逐渐缩短,这是一种具有特定性质的数据结构。它的特性就是只能在某一端增长或缩短,并且每次访问参数和局部变量时只能访问这一末端的单元,而不能访问内部的单元,比如当factorial(2)的存储空间位于末端时,只能访问它的参数和局部变量,而不能访问factorial(3)和main()的参数和局部变量。具有这种性质的数据结构称为堆栈或栈(Stack)。每个函数调用的参数和局部变量的存储空间(图里的一个小方框)称为一个栈帧(Stack Frame)。系统为每个程序的运行预留了栈空间,函数调用时就在这个栈空间里分配栈帧,函数返回时就释放栈帧。
在写一个递归函数时,你如何证明它是正确的?像上面那样跟踪函数的调用和返回过程算是一种办法,但只是factorial(3)就已经这么麻烦了,如果是factorial(100)呢?虽然我们已经证明了factorial(3)是正确的,因为它跟我们用数学公式计算的过程一样,结果也一样,但这不能代替factorial(100)的证明,你怎么办?别的函数你可以跟踪它的调用过程去证明它的正确性,因为每个函数都调用一次就返回了,但是对于递归函数,这么跟下去只会跟得你头都大了。事实上并不是每个函数调用都需要钻进去看的。我们在调用printf时没有钻进去看它是怎么打印的,我们只是相信它能打印,能正确完成它的工作,然后就继续写下面的代码了。在上一节中,我们写了distance和area函数,然后立刻测试证明了这两个函数是正确的,然后我们写area_point时调用了这两个函数:
return area(distance(x1, y1, x2, y2));
在写这一句的时候,我们需要钻进distance和area函数中去走一遍才知道我们调用得是否正确吗?不需要,因为我们已经相信这两个函数能正确工作了,也就是把座标传给distance它能返回正确的距离,把半径传给area它能返回正确的面积,因此调用它们去完成另外一件工作也应该是正确的。这种“相信”称为Leap of Faith,首先相信一些结论,然后再用它们去证明另外一些结论。
在写factorial(n)的代码时写到这个地方:
...... int recurse = factorial(n-1); int result = n * recurse; ......
这时,如果我们相信factorial(n-1)是正确的,也就是传给它n-1它就能返回(n-1)!,那么recurse就是(n-1)!,那么result就是n*(n-1)!,也就是n!,这正是我们要返回的factorial(n)的结果。当然这有点奇怪:我们还没写完factorial这个函数,凭什么要相信factorial(n-1)是正确的?可Leap of Faith本身就是Leap(跳跃)的,不是吗?如果你相信你正在写的递归函数是正确的,并调用它,然后在此基础上写完这个递归函数,那么它就会是正确的,从而值得你相信它正确。
这么说好像有点儿玄,我们从数学上严格证明一下factorial函数的正确性。刚才说了,factorial(n)的正确性依赖于factorial(n-1)的正确性,只要后者正确,在后者的结果上乘个n返回这一步显然也没有疑问,那么我们的函数实现就是正确的。因此要证明factorial(n)的正确性就是要证明factorial(n-1)的正确性,同理,要证明factorial(n-1)的正确性就是要证明factorial(n-2)的正确性,依此类推下去,最后是:要证明factorial(1)的正确性就是要证明factorial(0)的正确性。而factorial(0)的正确性不依赖于别的函数,它就是程序中的一个小的分支return 1;,这个1是我们根据阶乘的定义写的,肯定是正确的,因此factorial(1)也正确,因此factorial(2)也正确,依此类推,最后factorial(n)也是正确的。其实这就是中学时讲的数学归纳法(Mathematical Induction),用数学归纳法来证明只需要证明两点:Base Case正确,递推关系正确。写递归函数时一定要记得写Base Case,否则即使递推关系正确,整个函数也不正确。如果factorial函数漏掉了Base Case:
int factorial(int n)
{
int recurse = factorial(n-1);
int result = n * recurse;
return result;
}那么这个函数就会永远调用下去,直到系统为程序预留的栈空间耗尽程序崩溃(段错误)为止,这称为无穷递归(Infinite recursion)。
到目前为止我们只学习了全部C语言语法的一个小的子集,但是现在应该告诉你:这个子集是完备的,它本身就可以作为一门编程语言了,以后还要学很多的C语言特性,但全部都可以用已经学的这些特性来代替。也就是说,以后要学的C语言特性使得写程序更加方便,但不是必不可少的,现在学的这些已经完全覆盖了“程序和编程语言”一节讲的五种基本指令了。有的读者会说循环还没讲到呢,是的,循环下一章才讲,但有一个重要的结论就是递归和循环是等价的,用循环能做的事用递归都能做,反之亦然,事实上有的编程语言(如某些LISP)只有递归而没有循环。计算机硬件能做的所有事情就是数据存取、运算、测试和分支、循环(或递归),在计算机上运行的高级语言写的程序当然也不可能做到更多的事情,虽然高级语言有丰富的语法特性,但也只是为做这些事情提供一些方便。那么,为什么计算机是这样设计的?为什么想到计算机需要具有这几种功能,而不是更多或者更少?这些要归功于早期的计算机科学家,例如Alan Turing,他们在计算机还没有诞生的年代从数学理论上为计算机的设计指明了方向。有兴趣的读者可以参考有关计算理论的教材,例如[IATLC]。
递归绝不只是为解决一些奇技淫巧的数学题用的(例如很多编程书都能查到的汉诺塔问题,本书不打算讲这种无实际意义的题目),它是计算机的精髓所在,也是编程语言的精髓所在。我们学习C语言的语法时已经看到很多的递归定义了,例如:
函数调用的语法是用实参定义的,实参是用表达式定义的,而表达式又是用函数调用定义的,因为函数调用也是表达式的一种。
if/else是用两个子语句定义的,子语句又是用if/else定义的,因为if/else也是语句的一种。
可见编译器在翻译我们写的程序时一定也用了大量的递归。有关编译器的原理最经典的参考书是[Dragon Book]。
1、编写递归函数求两个正整数a和b的最大公约数(GCD,Greatest Common Divisor),使用Euclid算法:
如果a除以b能整除,则最大公约数是b。
否则,最大公约数等于b和a%b的最大公约数。
Euclid算法是很容易证明的,请读者自己证明一下为什么这么算就能算出最大公约数。
2、编写递归函数求Fibonacci数列的第n项,这个数列是这样定义的:
fib(0)=1
fib(1)=1
fib(n)=fib(n-1)+fib(n-2)
上面两个看似毫不相干的问题之间却有一个有意思的联系:
- Lamé定理
如果Euclid算法需要k步来计算两个数的GCD,那么这两个数之中较小的一个必然大于等于Fibonacci数列的第k项。
感兴趣的读者可以参考[SICP]第1.2节的简略证明。