计算机存储的最小单位是字节(Byte),一个字节通常是8个bit。C语言规定char型占一个字节的存储空间。如果这8个bit按无符号整数来解释,则取值范围是0~255,如果按有符号整数来解释,则取值范围是-128~127。C语言规定了signed和unsigned两个关键字,unsigned char型表示无符号数,signed char型表示有符号数。
那么不带signed或unsigned关键字的char型呢?C标准规定这是Implementation Defined,编译器可以定义char型是无符号的,也可以定义char型是有符号的,在该编译器所对应的体系结构上哪种实现效率高就可以采用哪种实现,x86平台的gcc定义char是有符号的。这也是C标准的Rationale之一:优先考虑效率,而可移植性尚在其次。这就要求程序员非常清楚这些规则,如果你要写可移植的代码,就必须清楚哪些写法是不可移植的,应该避免使用。另一方面,写不可移植的代码有时候也是必要的,比如Linux内核代码使用了很多gcc特性以得到最佳的执行效率,在写的时候就没打算用别的编译器编译,也就没考虑可移植性的问题。如果要写不可移植的代码,你也必须清楚代码中的哪些部分是不可移植的,以及为什么要这样写,如果不是为了效率,一般来说就没有理由故意写不可移植的代码。从现在开始,我们会接触到很多Implementation Defined的特性,C语言与平台和编译器是密不可分的,离开了具体的平台和编译器讨论C语言,就只能讨论到本书第一部分的程度了。注意,ASCII码的取值范围是0~127,所以不管char型是有符号的还是无符号的,存一个ASCII码都没有问题,一般来说,如果用char型存ASCII码字符,就不必明确写signed还是unsigned,如果把char型当作8位的整数来用,为了可移植性就必须写明是signed还是unsigned。
Implementation-defined、Unspecified和Undefined
在C标准中没有做明确规定的地方会用Implementation-defined、Unspecified或Undefined来表述,在本书中有时把这三种情况统称为“未明确定义”的。这三种情况到底有什么不同呢?
我们刚才看到一种Implementation-defined的情况,C标准没有明确规定char是有符号的还是无符号的,但是要求编译器必须对此做出明确规定,并写在编译器的文档中。
而对于Unspecified的情况,往往有几种可选的处理方式,C标准没有明确规定按哪种方式处理,编译器可以自己决定,并且也不必写在编译器的文档中,这样即使用同一个编译器的不同版本来编译也可能得到不同的结果,因为编译器没有在文档中明确写它会怎么处理,那么不同版本的编译器就可以选择不同的处理方式,比如下一章我们会讲到一个函数调用的各个实参表达式按什么顺序求值是Unspecified的。
Undefined的情况则是完全不确定的,C标准没规定怎么处理,编译器很可能也没规定,甚至也没做出错处理,有很多Undefined的情况是编译器是检查不出来的,最终会导致运行时错误,比如数组访问越界就是Undefined的。
初学者看到这些规则通常会很不舒服,觉得这不是在学编程而是在啃法律条文,结果越学越泄气。是的,C语言并不像一个数学定理那样完美,现实世界里的东西总是不够完美的。但还好啦,C程序员已经很幸福了,只要严格遵照C标准来写代码,不要去触碰那些阴暗角落,写出来的代码就有很好的可移植性。想想那些可怜的JavaScript程序员吧,他们甚至连一个可以遵照的标准都没有,一个浏览器一个样,因而不得不为每一种浏览器的每一个版本分别写不同的代码。
除了char型之外,整数类型还有short int(或者简写为short)、int、long int(或者简写为long)、long long int(或者简写为long long)几种,这些类型都可以加上signed或unsigned关键字表示有符号或无符号数。那么有符号数在计算机中的表示形式是Sign and Magnitude、1's Complement还是2's Complement?C标准也没有明确规定,也是Implementation Defined。大多数体系结构都采用2's Complement表示形式和加减运算规则,x86平台也是如此。还有一点要注意,除了char型以外的这些整数类型如果不明确写signed或unsigned关键字都表示有符号数,这一点是C标准明确规定的,不是Implementation Defined。
除了char型在C标准中明确规定占一个字节之外,其它整数类型占几个字节都是Implementation Defined。通常的编译器实现遵守ILP32或LP64规范,如下表所示。
ILP32这个缩写的意思是int(I)、long(L)和指针(P)类型都占32位,通常32位计算机的C编译器采用这种规范,x86平台的gcc也是如此。LP64是指long(L)和指针占64位,通常64位计算机的C编译器采用这种规范。指针类型的长度总是和计算机的位数一致,至于什么是计算机的位数,指针又是什么,以后再详细解释。从现在开始本书做以下约定:在以后的陈述中,缺省平台是x86/Linux/gcc,遵循ILP32,并且char是有符号的,我不会每次都加以说明,但说到其它平台时我会明确指出是什么平台。
以前我们只用到10进制的整数常量,其实在C语言中也可以用八进制和十六进制的整数常量[23]。八进制整数常量以0开头,后面的数字只能是0~7,例如022,因此十进制的整数常量就不能以0开头了,否则无法和八进制区分。十六进制整数常量以0x或0X开头,后面的数字可以是0~9、a~f和A~F。在“字符类型与字符编码”一节讲过一种转义序列,以\或\x加八进制或十六进制数字表示,这种表示方式相当于把八进制和十六进制整数常量开头的0替换成\了。
整数常量还可以在末尾在加u或U表示“unsigned”,加l或L表示“long”,加ll或LL表示“long long”,例如0x1234U,98765ULL等。但事实上u、l、ll这几种后缀和上面讲的unsigned、long、long long关键字并不是一一对应的。这个对应关系比较复杂,准确的描述如下图所示(出自[C99]条款6.4.4.1)。
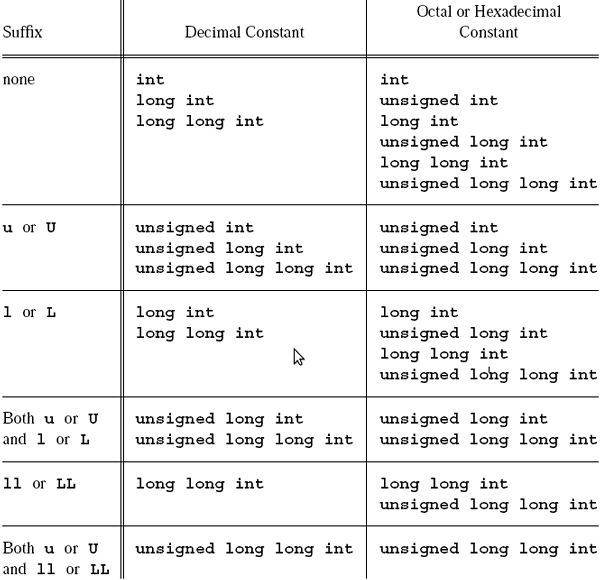
给定一个整数常量,比如1234U,那么它应该属于“u or U”这一行的Decimal Constant这一列,这个表格单元中列了三种类型unsigned int、unsigned long int、unsigned long long int,从上到下找出第一个足够长的类型可以表示1234这个数,那么它就是这个整数常量的类型,如果int是32位的那么unsigned int就可以表示。
再比如0xffff0000,应该属于第一行none的第二列Octal or Hexadecimal Constant,这一列有六种类型int、unsigned int、long int、unsigned long int、long long int、unsigned long long int,第一个类型int表示不了0xffff0000这么大的数,我们写这个十六进制常量是要表示一个正数,而它的MSB(第31位)是1,如果按有符号int类型来解释就成了负数了,第二个类型unsigned int可以表示这个数,所以这个十六进制常量的类型应该算unsigned int。
最后总结一下哪些类型属于整型这个大的概念。整型包括本节讲的有符号和无符号的char、int、long、long long,还包括以后要讲的Bit-field,此外,枚举常量就是int型的,所以也属于整型。
[23] 有些编译器(比如gcc)也支持二进制的整数常量,以0b或0B开头,比如0b0001111,但二进制的整数常量从未进入C标准,只是某些编译器的扩展,所以不建议使用,由于二进制和八进制、十六进制的对应关系非常明显,用八进制或十六进制常量完全可以代替使用二进制常量。