我们知道,一个磁盘可以划分成多个分区,每个分区必须先用格式化工具(例如某种mkfs命令)格式化成某种格式的文件系统,然后才能存储文件,格式化的过程会在磁盘上写一些管理存储布局的信息。下图是一个磁盘分区格式化成ext2文件系统后的存储布局。
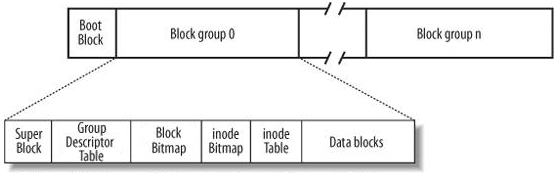
文件系统中存储的最小单位是块(Block),一个块究竟多大是在格式化时确定的,例如mke2fs的-b选项可以设定块大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的,就是1KB,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。启动块之后才是ext2文件系统的开始,ext2文件系统将整个分区划成若干个同样大小的块组(Block Group),每个块组都由以下部分组成。
- 超级块(Super Block)
描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次
mount的时间等等。超级块在每个块组的开头都有一份拷贝。- 块组描述符表(GDT,Group Descriptor Table)
由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核只用到第0个块组中的拷贝,当执行
e2fsck检查文件系统一致性时,第0个块组中的超级块和块组描述符表就会拷贝到其它块组,这样当第0个块组的开头意外损坏时就可以用其它拷贝来恢复,从而减少损失。- 块位图(Block Bitmap)
一个块组中的块是这样利用的:数据块(Data Block)存储所有文件的数据,比如某个分区的块大小是1024字节,某个文件是2049字节,那么就需要三个数据块来存,即使第三个块只存了一个字节也需要占用一个整块;超级块、块组描述符表、块位图、inode位图、inode表这几部分存储该块组的描述信息。那么如何知道哪些块已经用来存储文件数据或其它描述信息,哪些块仍然空闲可用呢?块位图就是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个bit代表本块组中的一个块,这个bit为1表示该块已用,这个bit为0表示该块空闲可用。
为什么用
df命令统计整个磁盘的已用空间非常快呢?因为只需要查看每个块组的块位图即可,而不需要搜遍整个分区。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。与此相联系的另一个问题是:在格式化一个分区时究竟会划出多少个块组呢?主要的限制在于块位图本身必须只占一个块。用
mke2fs格式化时默认块大小是1024字节,可以用-b参数指定块大小,现在设块大小指定为b字节,那么一个块可以有8b个bit,这样大小的一个块位图就可以表示8b个块的占用情况,因此一个块组最多可以有8b个块,如果整个分区有s个块,那么就可以有s/(8b)个块组。格式化时可以用-g参数指定一个块组有多少个块,但是通常不需要手动指定,mke2fs工具会计算出最优的数值。- inode位图(inode Bitmap)
和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。
- inode表(inode Table)
我们知道,一个文件除了数据需要存储之外,一些描述信息也需要存储,例如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时间等,也就是
ls -l命令看到的那些信息,这些信息存在inode中而不是数据块中。每个文件都有一个inode,一个块组中的所有inode组成了inode表。inode表占多少个块在格式化时就要决定并写入块组描述符中,
mke2fs格式化工具的默认策略是一个块组有多少个8KB就分配多少个inode。由于数据块占了整个块组的绝大部分,也可以近似认为数据块有多少个8KB就分配多少个inode,换句话说,如果平均每个文件的大小是8KB,当分区存满的时候inode表会得到比较充分的利用,数据块也不浪费。如果这个分区存的都是很大的文件(比如电影),则数据块用完的时候inode会有一些浪费,如果这个分区存的都是很小的文件(比如源代码),则有可能数据块还没用完inode就已经用完了,数据块可能有很大的浪费。如果用户在格式化时能够对这个分区以后要存储的文件大小做一个预测,也可以用mke2fs的-i参数手动指定每多少个字节分配一个inode。- 数据块
根据不同的文件类型有以下几种情况
对于常规文件,文件的数据存储在数据块中。
对于目录,该目录下的所有文件名和目录名存储在数据块中,注意文件名保存在它所在目录的数据块中,除文件名之外,
ls -l命令看到的其它信息都保存在该文件的inode中。注意这个概念:目录也是一种文件,是一种特殊类型的文件。对于符号链接,如果目标路径名较短则直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存。
设备文件、FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中。
现在做几个小实验来理解这些概念。例如在home目录下ls -l:
$ ls -l total 32 drwxr-xr-x 114 akaedu akaedu 12288 2008-10-25 11:33 akaedu drwxr-xr-x 114 ftp ftp 4096 2008-10-25 10:30 ftp drwx------ 2 root root 16384 2008-07-04 05:58 lost+found
为什么各目录的大小都是4096的整数倍?因为这个分区的块大小是4096,目录的大小总是数据块的整数倍。为什么有的目录大有的目录小?因为目录的数据块保存着它下边所有文件和目录的名字,如果一个目录中的文件很多,一个块装不下这么多文件名,就可能分配更多的数据块给这个目录。再比如:
$ ls -l /dev ...... prw-r----- 1 syslog adm 0 2008-10-25 11:39 xconsole crw-rw-rw- 1 root root 1, 5 2008-10-24 16:44 zero
xconsole文件的类型是p(表示pipe),是一个FIFO文件,后面会讲到它其实是一块内核缓冲区的标识,不在磁盘上保存数据,因此没有数据块,文件大小是0。zero文件的类型是c,表示字符设备文件,它代表内核中的一个设备驱动程序,也没有数据块,原本应该写文件大小的地方写了1, 5这两个数字,表示主设备号和次设备号,访问该文件时,内核根据设备号找到相应的驱动程序。再比如:
$ touch hello $ ln -s ./hello halo $ ls -l total 0 lrwxrwxrwx 1 akaedu akaedu 7 2008-10-25 15:04 halo -> ./hello -rw-r--r-- 1 akaedu akaedu 0 2008-10-25 15:04 hello
文件hello是刚创建的,字节数为0,符号链接文件halo指向hello,字节数却是7,为什么呢?其实7就是“./hello”这7个字符,符号链接文件就保存着这样一个路径名。再试试硬链接:
$ ln ./hello hello2 $ ls -l total 0 lrwxrwxrwx 1 akaedu akaedu 7 2008-10-25 15:08 halo -> ./hello -rw-r--r-- 2 akaedu akaedu 0 2008-10-25 15:04 hello -rw-r--r-- 2 akaedu akaedu 0 2008-10-25 15:04 hello2
hello2和hello除了文件名不一样之外,别的属性都一模一样,并且hello的属性发生了变化,第二栏的数字原本是1,现在变成2了。从根本上说,hello和hello2是同一个文件在文件系统中的两个名字,ls -l第二栏的数字是硬链接数,表示一个文件在文件系统中有几个名字(这些名字可以保存在不同目录的数据块中,或者说可以位于不同的路径下),硬链接数也保存在inode中。既然是同一个文件,inode当然只有一个,所以用ls -l看它们的属性是一模一样的,因为都是从这个inode里读出来的。再研究一下目录的硬链接数:
$ mkdir a $ mkdir a/b $ ls -ld a drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 a $ ls -la a total 20 drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 . drwxr-xr-x 115 akaedu akaedu 12288 2008-10-25 16:14 .. drwxr-xr-x 2 akaedu akaedu 4096 2008-10-25 16:15 b $ ls -la a/b total 8 drwxr-xr-x 2 akaedu akaedu 4096 2008-10-25 16:15 . drwxr-xr-x 3 akaedu akaedu 4096 2008-10-25 16:15 ..
首先创建目录a,然后在它下面创建子目录a/b。目录a的硬链接数是3,这3个名字分别是当前目录下的a,a目录下的.和b目录下的..。目录b的硬链接数是2,这两个名字分别是a目录下的b和b目录下的.。注意,目录的硬链接只能这种方式创建,用ln命令可以创建目录的符号链接,但不能创建目录的硬链接。
如果要格式化一个分区来研究文件系统格式则必须有一个空闲的磁盘分区,为了方便实验,我们把一个文件当作分区来格式化,然后分析这个文件中的数据来印证上面所讲的要点。首先创建一个1MB的文件并清零:
$ dd if=/dev/zero of=fs count=256 bs=4K
我们知道cp命令可以把一个文件拷贝成另一个文件,而dd命令可以把一个文件的一部分拷贝成另一个文件。这个命令的作用是把/dev/zero文件开头的1M(256×4K)字节拷贝成文件名为fs的文件。刚才我们看到/dev/zero是一个特殊的设备文件,它没有磁盘数据块,对它进行读操作传给设备号为1, 5的驱动程序。/dev/zero这个文件可以看作是无穷大的,不管从哪里开始读,读出来的都是字节0x00。因此这个命令拷贝了1M个0x00到fs文件。if和of参数表示输入文件和输出文件,count和bs参数表示拷贝多少次,每次拷多少字节。
做好之后对文件fs进行格式化,也就是把这个文件的数据块合起来看成一个1MB的磁盘分区,在这个分区上再划分出块组。
$ mke2fs fs mke2fs 1.40.2 (12-Jul-2007) fs is not a block special device. Proceed anyway? (y,n) (输入y回车) Filesystem label= OS type: Linux Block size=1024 (log=0) Fragment size=1024 (log=0) 128 inodes, 1024 blocks 51 blocks (4.98%) reserved for the super user First data block=1 Maximum filesystem blocks=1048576 1 block group 8192 blocks per group, 8192 fragments per group 128 inodes per group Writing inode tables: done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 27 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
格式化一个真正的分区应该指定块设备文件名,例如/dev/sda1,而这个fs是常规文件而不是块设备文件,mke2fs认为用户有可能是误操作了,所以给出提示,要求确认是否真的要格式化,输入y回车完成格式化。
现在fs的大小仍然是1MB,但不再是全0了,其中已经有了块组和描述信息。用dumpe2fs工具可以查看这个分区的超级块和块组描述符表中的信息:
$ dumpe2fs fs dumpe2fs 1.40.2 (12-Jul-2007) Filesystem volume name: <none> Last mounted on: <not available> Filesystem UUID: 8e1f3b7a-4d1f-41dc-8928-526e43b2fd74 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: resize_inode dir_index filetype sparse_super Filesystem flags: signed directory hash Default mount options: (none) Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 128 Block count: 1024 Reserved block count: 51 Free blocks: 986 Free inodes: 117 First block: 1 Block size: 1024 Fragment size: 1024 Reserved GDT blocks: 3 Blocks per group: 8192 Fragments per group: 8192 Inodes per group: 128 Inode blocks per group: 16 Filesystem created: Sun Dec 16 14:56:59 2007 Last mount time: n/a Last write time: Sun Dec 16 14:56:59 2007 Mount count: 0 Maximum mount count: 30 Last checked: Sun Dec 16 14:56:59 2007 Check interval: 15552000 (6 months) Next check after: Fri Jun 13 14:56:59 2008 Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Default directory hash: tea Directory Hash Seed: 6d0e58bd-b9db-41ae-92b3-4563a02a5981 Group 0: (Blocks 1-1023) Primary superblock at 1, Group descriptors at 2-2 Reserved GDT blocks at 3-5 Block bitmap at 6 (+5), Inode bitmap at 7 (+6) Inode table at 8-23 (+7) 986 free blocks, 117 free inodes, 2 directories Free blocks: 38-1023 Free inodes: 12-128 128 inodes per group, 8 inodes per block, so: 16 blocks for inode table
根据上面讲过的知识简单计算一下,块大小是1024字节,1MB的分区共有1024个块,第0个块是启动块,启动块之后才算ext2文件系统的开始,因此Group 0占据第1个到第1023个块,共1023个块。块位图占一个块,共有1024×8=8192个bit,足够表示这1023个块了,因此只要一个块组就够了。默认是每8KB分配一个inode,因此1MB的分区对应128个inode,这些数据都和dumpe2fs的输出吻合。
用常规文件制作而成的文件系统也可以像磁盘分区一样mount到某个目录,例如:
$ sudo mount -o loop fs /mnt $ cd /mnt/ $ ls -la total 17 drwxr-xr-x 3 akaedu akaedu 1024 2008-10-25 12:20 . drwxr-xr-x 21 root root 4096 2008-08-18 08:54 .. drwx------ 2 root root 12288 2008-10-25 12:20 lost+found
-o loop选项告诉mount这是一个常规文件而不是一个块设备文件。mount会把它的数据块中的数据当作分区格式来解释。文件系统格式化之后在根目录下自动生成三个子目录:.,..和lost+found。其它子目录下的.表示当前目录,..表示上一级目录,而根目录的.和..都表示根目录本身。lost+found目录由e2fsck工具使用,如果在检查磁盘时发现错误,就把有错误的块挂在这个目录下,因为这些块不知道是谁的,找不到主,就放在这里“失物招领”了。
现在可以在/mnt目录下添加删除文件,这些操作会自动保存到文件fs中。然后把这个分区umount下来,以确保所有的改动都保存到文件中了。
$ sudo umount /mnt
注意,下面的实验步骤是对新创建的文件系统做的,如果你在文件系统中添加删除过文件,跟着做下面的步骤时结果可能和我写的不太一样,不过也不影响理解。
现在我们用二进制查看工具查看这个文件系统的所有字节,并且同dumpe2fs工具的输出信息相比较,就可以很好地理解文件系统的存储布局了。
$ od -tx1 -Ax fs 000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 * 000400 80 00 00 00 00 04 00 00 33 00 00 00 da 03 00 00 000410 75 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 ......
其中以*开头的行表示这一段数据全是零因此省略了。下面详细分析od输出的信息。
从000000开始的1KB是启动块,由于这不是一个真正的磁盘分区,启动块的内容全部为零。从000400到0007ff的1KB是超级块,对照着dumpe2fs的输出信息,详细分析如下:

超级块中从0004d0到末尾的204个字节是填充字节,保留未用,上图未画出。注意,ext2文件系统中各字段都是按小端存储的,如果把字节在文件中的位置看作地址,那么靠近文件开头的是低地址,存低字节。各字段的位置、长度和含义详见[ULK]。
从000800开始是块组描述符表,这个文件系统较小,只有一个块组描述符,对照着dumpe2fs的输出信息分析如下:
... Group 0: (Blocks 1-1023) Primary superblock at 1, Group descriptors at 2-2 Reserved GDT blocks at 3-5 Block bitmap at 6 (+5), Inode bitmap at 7 (+6) Inode table at 8-23 (+7) 986 free blocks, 117 free inodes, 2 directories Free blocks: 38-1023 Free inodes: 12-128 ...

整个文件系统是1MB,每个块是1KB,应该有1024个块,除去启动块还有1023个块,分别编号为1-1023,它们全都属于Group 0。其中,Block 1是超级块,接下来的块组描述符指出,块位图是Block 6,因此中间的Block 2-5是块组描述符表,其中Block 3-5保留未用。块组描述符还指出,inode位图是Block 7,inode表是从Block 8开始的,那么inode表到哪个块结束呢?由于超级块中指出每个块组有128个inode,每个inode的大小是128字节,因此共占16个块,inode表的范围是Block 8-23。
从Block 24开始就是数据块了。块组描述符中指出,空闲的数据块有986个,由于文件系统是新创建的,空闲块是连续的Block 38-1023,用掉了前面的Block 24-37。从块位图中可以看出,前37位(前4个字节加最后一个字节的低5位)都是1,就表示Block 1-37已用:
001800 ff ff ff ff 1f 00 00 00 00 00 00 00 00 00 00 00 001810 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 * 001870 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 80 001880 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff *
在块位图中,Block 38-1023对应的位都是0(一直到001870那一行最后一个字节的低7位),接下来的位已经超出了文件系统的空间,不管是0还是1都没有意义。可见,块位图每个字节中的位应该按从低位到高位的顺序来看。以后随着文件系统的使用和添加删除文件,块位图中的1就变得不连续了。
块组描述符指出,空闲的inode有117个,由于文件系统是新创建的,空闲的inode也是连续的,inode编号从1到128,空闲的inode编号从12到128。从inode位图可以看出,前11位都是1,表示前11个inode已用:
001c00 ff 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001c10 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff *
以后随着文件系统的使用和添加删除文件,inode位图中的1就变得不连续了。
001c00这一行的128位就表示了所有inode,因此下面的行不管是0还是1都没有意义。已用的11个inode中,前10个inode是被ext2文件系统保留的,其中第2个inode是根目录,第11个inode是lost+found目录,块组描述符也指出该组有两个目录,就是根目录和lost+found。
探索文件系统还有一个很有用的工具debugfs,它提供一个命令行界面,可以对文件系统做各种操作,例如查看信息、恢复数据、修正文件系统中的错误。下面用debugfs打开fs文件,然后在提示符下输入help看看它都能做哪些事情:
$ debugfs fs debugfs 1.40.2 (12-Jul-2007) debugfs: help
在debugfs的提示符下输入stat /命令,这时在新的一屏中显示根目录的inode信息:
Inode: 2 Type: directory Mode: 0755 Flags: 0x0 Generation: 0 User: 1000 Group: 1000 Size: 1024 File ACL: 0 Directory ACL: 0 Links: 3 Blockcount: 2 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 atime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 mtime: 0x4764cc3b -- Sun Dec 16 14:56:59 2007 BLOCKS: (0):24 TOTAL: 1
按q退出这一屏,然后用quit命令退出debugfs:
debugfs: quit
把以上信息和od命令的输出对照起来分析:
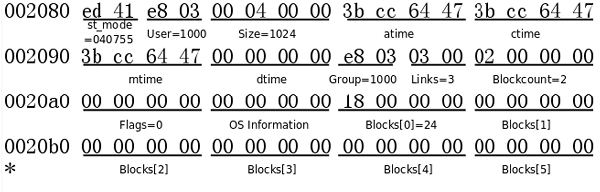
上图中的st_mode以八进制表示,包含了文件类型和文件权限,最高位的4表示文件类型为目录(各种文件类型的编码详见stat(2)),低位的755表示权限。Size是1024,说明根目录现在只有一个数据块。Links为3表示根目录有三个硬链接,分别是根目录下的.和..,以及lost+found子目录下的..。注意,虽然我们通常用/表示根目录,但是并没有名为/的硬链接,事实上,/是路径分隔符,不能在文件名中出现。这里的Blockcount是以512字节为一个块来数的,并非格式化文件系统时所指定的块大小,磁盘的最小读写单位称为扇区(Sector),通常是512字节,所以Blockcount是磁盘的物理块数量,而非分区的逻辑块数量。根目录数据块的位置由上图中的Blocks[0]指出,也就是第24个块,它在文件系统中的位置是24×0x400=0x6000,从od命令的输出中找到006000地址,它的格式是这样:

目录的数据块由许多不定长的记录组成,每条记录描述该目录下的一个文件,在上图中用框表示。第一条记录描述inode号为2的文件,也就是根目录本身,该记录的总长度为12字节,其中文件名的长度为1字节,文件类型为2(见下表,注意此处的文件类型编码和st_mode不一致),文件名是.。
表 29.1. 目录中的文件类型编码
| 编码 | 文件类型 |
|---|---|
| 0 | Unknown |
| 1 | Regular file |
| 2 | Directory |
| 3 | Character device |
| 4 | Block device |
| 5 | Named pipe |
| 6 | Socket |
| 7 | Symbolic link |
第二条记录也是描述inode号为2的文件(根目录),该记录总长度为12字节,其中文件名的长度为2字节,文件类型为2,文件名字符串是..。第三条记录一直延续到该数据块的末尾,描述inode号为11的文件(lost+found目录),该记录的总长度为1000字节(和前面两条记录加起来是1024字节),文件类型为2,文件名字符串是lost+found,后面全是0字节。如果要在根目录下创建新的文件,可以把第三条记录截短,在原来的0字节处创建新的记录。如果该目录下的文件名太多,一个数据块不够用,则会分配新的数据块,块编号会填充到inode的Blocks[1]字段。
debugfs也提供了cd、ls等命令,不需要mount就可以查看这个文件系统中的目录,例如用ls查看根目录:
2 (12) . 2 (12) .. 11 (1000) lost+found
列出了inode号、记录长度和文件名,这些信息都是从根目录的数据块中读出来的。
如果一个文件有多个数据块,这些数据块很可能不是连续存放的,应该如何寻址到每个块呢?根据上面的分析,根目录的数据块是通过其inode中的索引项Blocks[0]找到的,事实上,这样的索引项一共有15个,从Blocks[0]到Blocks[14],每个索引项占4字节。前12个索引项都表示块编号,例如上面的例子中Blocks[0]字段保存着24,就表示第24个块是该文件的数据块,如果块大小是1KB,这样可以表示从0字节到12KB的文件。如果剩下的三个索引项Blocks[12]到Blocks[14]也是这么用的,就只能表示最大15KB的文件了,这是远远不够的,事实上,剩下的三个索引项都是间接索引。
索引项Blocks[12]所指向的块并非数据块,而是称为间接寻址块(Indirect Block),其中存放的都是类似Blocks[0]这种索引项,再由索引项指向数据块。设块大小是b,那么一个间接寻址块中可以存放b/4个索引项,指向b/4个数据块。所以如果把Blocks[0]到Blocks[12]都用上,最多可以表示b/4+12个数据块,对于块大小是1K的情况,最大可表示268K的文件。如下图所示,注意文件的数据块编号是从0开始的,Blocks[0]指向第0个数据块,Blocks[11]指向第11个数据块,Blocks[12]所指向的间接寻址块的第一个索引项指向第12个数据块,依此类推。
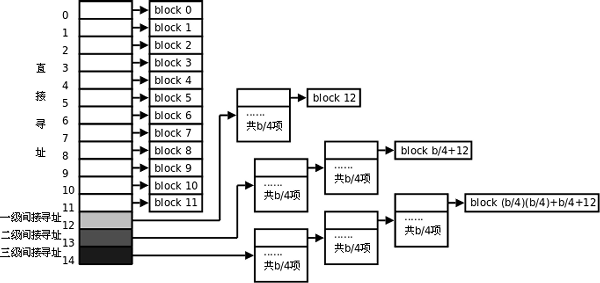
从上图可以看出,索引项Blocks[13]指向两级的间接寻址块,最多可表示(b/4)2+b/4+12个数据块,对于1K的块大小最大可表示64.26MB的文件。索引项Blocks[14]指向三级的间接寻址块,最多可表示(b/4)3+(b/4)2+b/4+12个数据块,对于1K的块大小最大可表示16.06GB的文件。
可见,这种寻址方式对于访问不超过12个数据块的小文件是非常快的,访问文件中的任意数据只需要两次读盘操作,一次读inode(也就是读索引项)一次读数据块。而访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。实际上,磁盘中的inode和数据块往往已经被内核缓存了,读大文件的效率也不会太低。
本节简要介绍一下文件和目录操作常用的系统函数,常用的文件操作命令如ls、cp、mv等也是基于这些函数实现的。本节的侧重点在于讲解这些函数的工作原理,而不是如何使用它们,理解了实现原理之后再看这些函数的用法就很简单了,请读者自己查阅Man Page了解其用法。
stat(2)函数读取文件的inode,然后把inode中的各种文件属性填入一个struct stat结构体传出给调用者。stat(1)命令是基于stat函数实现的。stat需要根据传入的文件路径找到inode,假设一个路径是/opt/file,则查找的顺序是:
读出inode表中第2项,也就是根目录的inode,从中找出根目录数据块的位置
从根目录的数据块中找出文件名为
opt的记录,从记录中读出它的inode号读出
opt目录的inode,从中找出它的数据块的位置从
opt目录的数据块中找出文件名为file的记录,从记录中读出它的inode号读出
file文件的inode
还有另外两个类似stat的函数:fstat(2)函数传入一个已打开的文件描述符,传出inode信息,lstat(2)函数也是传入路径传出inode信息,但是和stat函数有一点不同,当文件是一个符号链接时,stat(2)函数传出的是它所指向的目标文件的inode,而lstat函数传出的就是符号链接文件本身的inode。
access(2)函数检查执行当前进程的用户是否有权限访问某个文件,传入文件路径和要执行的访问操作(读/写/执行),access函数取出文件inode中的st_mode字段,比较一下访问权限,然后返回0表示允许访问,返回-1表示错误或不允许访问。
chmod(2)和fchmod(2)函数改变文件的访问权限,也就是修改inode中的st_mode字段。这两个函数的区别类似于stat/fstat。chmod(1)命令是基于chmod函数实现的。
chown(2)/fchown(2)/lchown(2)改变文件的所有者和组,也就是修改inode中的User和Group字段,只有超级用户才能正确调用这几个函数,这几个函数之间的区别类似于stat/fstat/lstat。chown(1)命令是基于chown函数实现的。
utime(2)函数改变文件的访问时间和修改时间,也就是修改inode中的atime和mtime字段。touch(1)命令是基于utime函数实现的。
truncate(2)和ftruncate(2)函数把文件截断到某个长度,如果新的长度比原来的长度短,则后面的数据被截掉了,如果新的长度比原来的长度长,则后面多出来的部分用0填充,这需要修改inode中的Blocks索引项以及块位图中相应的bit。这两个函数的区别类似于stat/fstat。
link(2)函数创建硬链接,其原理是在目录的数据块中添加一条新记录,其中的inode号字段和原文件相同。symlink(2)函数创建一个符号链接,这需要创建一个新的inode,其中st_mode字段的文件类型是符号链接,原文件的路径保存在inode中或者分配一个数据块来保存。ln(1)命令是基于link和symlink函数实现的。
unlink(2)函数删除一个链接。如果是符号链接则释放这个符号链接的inode和数据块,清除inode位图和块位图中相应的位。如果是硬链接则从目录的数据块中清除一条文件名记录,如果当前文件的硬链接数已经是1了还要删除它,就同时释放它的inode和数据块,清除inode位图和块位图中相应的位,这样就真的删除文件了。unlink(1)命令和rm(1)命令是基于unlink函数实现的。
rename(2)函数改变文件名,需要修改目录数据块中的文件名记录,如果原文件名和新文件名不在一个目录下则需要从原目录数据块中清除一条记录然后添加到新目录的数据块中。mv(1)命令是基于rename函数实现的,因此在同一分区的不同目录中移动文件并不需要复制和删除文件的inode和数据块,只需要一个改名操作,即使要移动整个目录,这个目录下有很多子目录和文件也要随着一起移动,移动操作也只是对顶级目录的改名操作,很快就能完成。但是,如果在不同的分区之间移动文件就必须复制和删除inode和数据块,如果要移动整个目录,所有子目录和文件都要复制删除,这就很慢了。
readlink(2)函数读取一个符号链接所指向的目标路径,其原理是从符号链接的inode或数据块中读出保存的数据,这就是目标路径。
mkdir(2)函数创建新的目录,要做的操作是在它的父目录数据块中添加一条记录,然后分配新的inode和数据块,inode的st_mode字段的文件类型是目录,在数据块中填两个记录,分别是.和..,由于..表示父目录,因此父目录的硬链接数要加1。mkdir(1)命令是基于mkdir函数实现的。
rmdir(2)函数删除一个目录,这个目录必须是空的(只包含.和..)才能删除,要做的操作是释放它的inode和数据块,清除inode位图和块位图中相应的位,清除父目录数据块中的记录,父目录的硬链接数要减1。rmdir(1)命令是基于rmdir函数实现的。
opendir(3)/readdir(3)/closedir(3)用于遍历目录数据块中的记录。opendir打开一个目录,返回一个DIR *指针代表这个目录,它是一个类似FILE *指针的句柄,closedir用于关闭这个句柄,把DIR *指针传给readdir读取目录数据块中的记录,每次返回一个指向struct dirent的指针,反复读就可以遍历所有记录,所有记录遍历完之后readdir返回NULL。结构体struct dirent的定义如下:
struct dirent {
ino_t d_ino; /* inode number */
off_t d_off; /* offset to the next dirent */
unsigned short d_reclen; /* length of this record */
unsigned char d_type; /* type of file */
char d_name[256]; /* filename */
};这些字段和图 29.6 “根目录的数据块”基本一致。这里的文件名d_name被库函数处理过,已经在结尾加了'\0',而图 29.6 “根目录的数据块”中的文件名字段不保证是以'\0'结尾的,需要根据前面的文件名长度字段确定文件名到哪里结束。
下面这个例子出自[K&R],作用是递归地打印出一个目录下的所有子目录和文件,类似ls -R。
例 29.1. 递归列出目录中的文件列表
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <dirent.h>
#include <stdio.h>
#include <string.h>
#define MAX_PATH 1024
/* dirwalk: apply fcn to all files in dir */
void dirwalk(char *dir, void (*fcn)(char *))
{
char name[MAX_PATH];
struct dirent *dp;
DIR *dfd;
if ((dfd = opendir(dir)) == NULL) {
fprintf(stderr, "dirwalk: can't open %s\n", dir);
return;
}
while ((dp = readdir(dfd)) != NULL) {
if (strcmp(dp->d_name, ".") == 0
|| strcmp(dp->d_name, "..") == 0)
continue; /* skip self and parent */
if (strlen(dir)+strlen(dp->d_name)+2 > sizeof(name))
fprintf(stderr, "dirwalk: name %s %s too long\n",
dir, dp->d_name);
else {
sprintf(name, "%s/%s", dir, dp->d_name);
(*fcn)(name);
}
}
closedir(dfd);
}
/* fsize: print the size and name of file "name" */
void fsize(char *name)
{
struct stat stbuf;
if (stat(name, &stbuf) == -1) {
fprintf(stderr, "fsize: can't access %s\n", name);
return;
}
if ((stbuf.st_mode & S_IFMT) == S_IFDIR)
dirwalk(name, fsize);
printf("%8ld %s\n", stbuf.st_size, name);
}
int main(int argc, char **argv)
{
if (argc == 1) /* default: current directory */
fsize(".");
else
while (--argc > 0)
fsize(*++argv);
return 0;
}然而这个程序还是不如ls -R健壮,它有可能死循环,思考一下什么情况会导致死循环。